

How AI is eating itself
AI slop, enshitification and the perpetual stew of data


Thanks for reading GAS STATION BREAKFAST! Subscribe for free to receive new posts about tech, design and behavioral patterns.
What is ‘AI Slop’?
The science of the ‘enshitification’
Digital pollution
Searching for humans
Processed food = Fast-food?
Data-centipede
The browser extension as protest
Sure, the old will die out, but will you improve?


What is ‘AI Slop’?
“Slop” means exactly what it sounds like: low-effort, AI-generated content that nobody asked for and nobody wants, but which clogs the pipes anyway. Not spam, which tries to sell you something. Slop exists simply to exist, to game an algorithm, to capture a fraction of attention in an economy where even garbage has monetary value.
“In Q1 2024, we took action against 631 million fake accounts... and in Q2 2024, we took action against 1.2 billion fake accounts on Facebook globally. We estimate that fake accounts represent approximately 4% of our worldwide monthly active users.”
— Meta Transparency Center, Community Standards Enforcement Report (2025)
The scale of synthetic actors now rivals human populations. Zombie Loops aka bots posting AI content that other bots like to boost engagement metrics. The mechanism works like photocopying a photocopy. Each generation loses fidelity. The weird stuff vanishes first. What remains converges toward bland, statistical average.






The science of the ‘enshitification’
Ilia Shumailov’s team published research in Nature in July 2024 demonstrating what happens when AI models train on data generated by other AIs: model collapse. The models approximate reality, always losing detail in translation, particularly at the extremes (Shumailov et al., 2024). After five generations of recursive training, they produce gibberish across language models, image generators, and other architectures.
“We find that indiscriminate use of model-generated content in training causes irreversible defects in the resulting models, in which tails of the original content distribution disappear. We refer to this effect as ‘model collapse’... what we see is AI spiralling into the abyss, feeding on its own mistakes and becoming increasingly clueless and repetitive.”
- Ilia Shumailov et al., AI models collapse when trained on recursively generated data

In 2023, publisher Hindawi retracted over 8,000 scientific articles from paper mills. By 2024, approximately one in fifty papers showed patterns suggesting paper mill origin.
Actually, entire AI-generated papers are slipping past peer review entirely. Researchers searching Google Scholar for the telltale phrase “As of my last knowledge update” found 115 different published articles relying on copy-pasted AI outputs (Lasser et al., 2025).
“In a sample of 53 articles from the Global International Journal of Innovative Research, 48 showed clear signs of being entirely AI-generated, with some even attaining a 100% similarity score on AI detection tools while falsely claiming affiliations with prestigious institutions.”
— Diomidis Spinellis, Professor of Software Engineering at Athens University of Economics and Business, Research Integrity and Peer Review (2025)

Digital pollution
I want to make the analogy with pollution. The chimney vomits dark clouds. The factory works fine. The people breathing the air get sick.
A study published in Societies in January 2025 found a significant negative correlation between frequent AI tool usage and critical thinking scores. People who used AI tools more often demonstrated measurably weaker ability to critically evaluate information and engage in reflective problem-solving. For my peers interested in behavioral science, the mechanism is known as cognitive offloading (delegating mental tasks to external systems).
Although we are absolutely baffled by how boomers fall into AI traps, data show that the effect hit younger users hardest. People aged 17-25 showed the highest dependence on AI and the sharpest decline in critical thinking scores. Higher education provided some buffer.

This isn’t about AI being inherently bad. The question is dosage and context. When the tool removes the struggle, it removes the exercise that builds neural pathways. The tool works. AI-generated answers are often correct. The efficiency gains are real. But the cost is losing the ability to evaluate whether what you’re being told is true.

Searching for humans
By late 2024, people started adding “reddit” to their Google searches specifically to get human answers instead of AI-generated SEO spam. The pattern became so widespread that Google integrated it into search functionality.
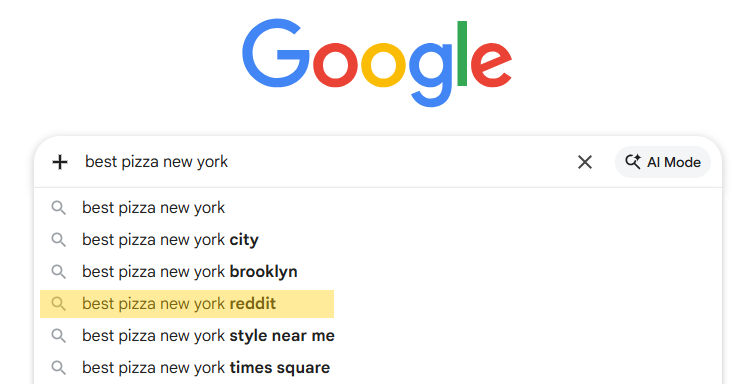
In December 2024, Reddit launched Reddit Answers, an AI-powered search tool designed to keep users on Reddit rather than sending them through Google. People fled to Reddit to escape AI, so Reddit deployed AI to surface the human content people were seeking.

When synthetic content floods general search, human-generated discussion becomes valuable specifically because it’s human. People trust Reddit comments more than polished articles because the comments show friction: disagreement, uncertainty, personal experience that resists easy optimization.
“For years, people have been adding ‘Reddit’ to their Google searches to skip generic answers and find real human advice. Reddit Answers feels like a natural evolution for a platform that’s already known as the place to go for real conversations... it’s about keeping people on Reddit for longer.”
- Redreach Blog, Reddit Answers: The AI Tool That’s Changing How You Search Reddit

Processed food = Fast-food?
Ultra-processed foods now make up over 50% of American calorie intake. The health effects track across multiple cohort studies: obesity, type 2 diabetes, cardiovascular disease, cancer, dementia.
What drives consumption isn’t that ultra-processed food is better, or even ‘appears to be better’ (the opposite). It’s cheaper, more convenient, heavily marketed, engineered to be hyperpalatable. When whole foods cost more and require time people don’t have, the processed alternative wins on every practical dimension despite worse health outcomes.
Watch the same pattern in information. Real reporting costs money. Slop is free. Real expertise takes years to develop. AI provides instant answers. Verification requires time and cognitive effort. Acceptance is immediate and effortless.
Nobody vilifies food processing as inherently evil. Pasteurization saves lives. Frozen vegetables retain nutrients. The question is degree and purpose. When processing exists to make food safer or more accessible, it serves human needs.

Same with AI. Using it to summarize a 50-page technical document? Reasonable. Using it to generate fake peer reviews or fraudulent research papers? System degradation. The technology doesn’t change; the application does.

Data-centipede
Tech leaders and research firms have come forward to explain that the era of training AI on purely human-generated data has reached its natural limit:
“We have achieved peak data and there’ll be no more... we might have reached a point where scraping more data from the web no longer yields the explosive growth in capability we once took for granted.”
— Ilya Sutskever, Co-founder of Safe Superintelligence Inc. (SSI) and former OpenAI Chief Scientist, NeurIPS 2024 / Kingy AI

“By 2030, synthetic data will completely overshadow real data in AI model training. You won’t be able to build high-quality, high-value AI models without synthetic data.”
— Vibha Chitkara, Principal Researcher at Gartner, Gartner Newsroom / Dataversity (2025)

The industry is currently navigating a shift where the “real data” curve is flattening while the “synthetic data” curve is expected to grow exponentially to meet the demand for model scaling.
But the industry’s solution is exactly what causes model collapse: training AI on AI-generated content. Some researchers think mixing synthetic with real data might work if you keep adding human-generated content alongside the synthetic, like it’s a perpetual stew. Other researchers found that when models train on predecessor-generated data, performance degrades as if they had only a fraction of the original training set (Kempe et al., 2024).
“Our results show that training on synthetic data leads to a ‘diminishing returns’ effect where the effective sample size is much smaller than the actual number of synthetic points. Essentially, the model ‘forgets’ the diversity of the real world because it is only learning the simplified patterns captured by the previous AI.”
— Julia Kempe, Silver Professor of Computer Science and Mathematics at NYU, arXiv / NYU Center for Data Science (2024)


The browser extension as protest
In October 2024, Australian artist Tega Brain released Slop Evader: a browser extension that filters Google searches to show only results from before November 30, 2022, the day ChatGPT launched (Brain, 2024).
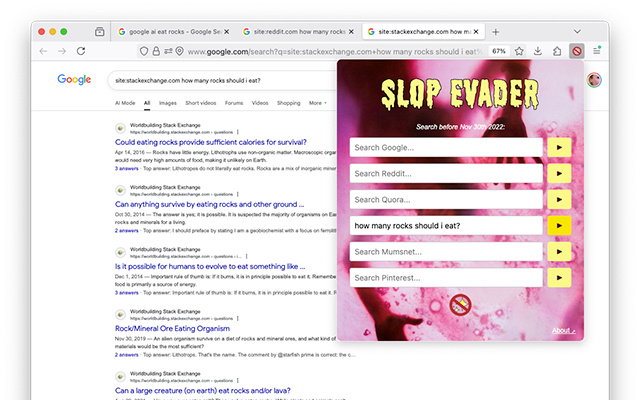
“This sowing of mistrust in our relationship with media is a huge thing. I’ve been thinking about ways to refuse it, and the simplest, dumbest way to do that is to only search before 2022.”
— Tega Brain, Associate Professor of Integrated Design and Media at NYU, The New York Times / “The World According to ChatGPT” (2024)
Thousands installed it. Multiple GitHub projects maintain AI blocklists for uBlock Origin. Tens of thousands of domains flagged as AI content farms, SEO spam sites, synthetic image sources. Users curate these lists collaboratively, building infrastructure for filtering slop the same way they built ad blockers.

Adaptive behavior. When the environment degrades, organisms that can’t leave develop filtering mechanisms.

Sure, the old will die out, but will you improve?
Seniors test poorly at detecting AI-generated content now. They trust photographs because photographs meant something for 70 years.
Younger users might develop better detection through exposure. “That’s AI” has become a slur in their lexicon. It doesn’t just mean artificial. but lazy, soulless, insulting. The phrase signals developing immunity, social antibodies against synthetic content.

Or maybe not. Everyone knows fast food isn’t healthy. Fifty years of nutrition education didn’t stop ultra-processed foods from becoming 50% of American diet. Convenience, price, and availability override knowledge.
People adapt by accepting degraded baseline, not by demanding better. You get used to sorting through slop. You develop shortcuts. You trust less, engage less, care less. The technical term is shifting baseline syndrome. Each generation accepts the degraded state they inherit as normal because they don’t remember better.
Your grandmother trusts too much. You trust nothing. Both are degraded states. Both are adaptations to an environment where truth is expensive and lies are free.

AI didn’t create distrust
Disinformation, fake news, algorithmic manipulation; none of this started with AI.
AI accelerates existing dynamics. What took a team to fake before now takes one person with a prompt. The barrier to entry collapsed. But the market for disinformation existed first. The incentive structure that rewards synthetic garbage existed first. The advertising model that pays for engagement regardless of quality existed first.
The Xerox machine didn’t cause document fraud. It made document fraud easier and cheaper, which revealed how much demand for document fraud existed. That’s what’s happening here. Not new slop. Just more of it.


Trust is a key topic in Design strategy applied to AI, I have written a couple of articles on the topic:
If you want to read about how AI makes itself acceptable, or not, and how to design for trust when building an AI companion, check my article Building AI trust.
If you want to read about why we accept opaque minds but reject transparent machines , check my article The trust paradox.